
Why the open-source data world is buzzing about CMU’s new columnar format — and why Parquet’s decade-long reign might actually be ending
When I first heard about “yet another file format,” I rolled my eyes so hard I nearly sprained something. We’ve been here before. Every few years, someone announces the revolutionary format that will replace Parquet and save us all. I’ve watched Lance, Nimble, and a dozen others come through promising the moon.
But F3 is different. And I’m not just saying that because it’s from CMU ( Carnegie-Mellon University )(though let’s be real, they’ve earned some credibility). I’m saying it because I spent the last month actually testing it, and it solved problems I didn’t even know I could solve.
Warning: F3 project is a research prototype. You should not use it in production.
The Parquet Reality Check
Here’s what nobody tells you in those glossy “Why Parquet is Amazing” blog posts:
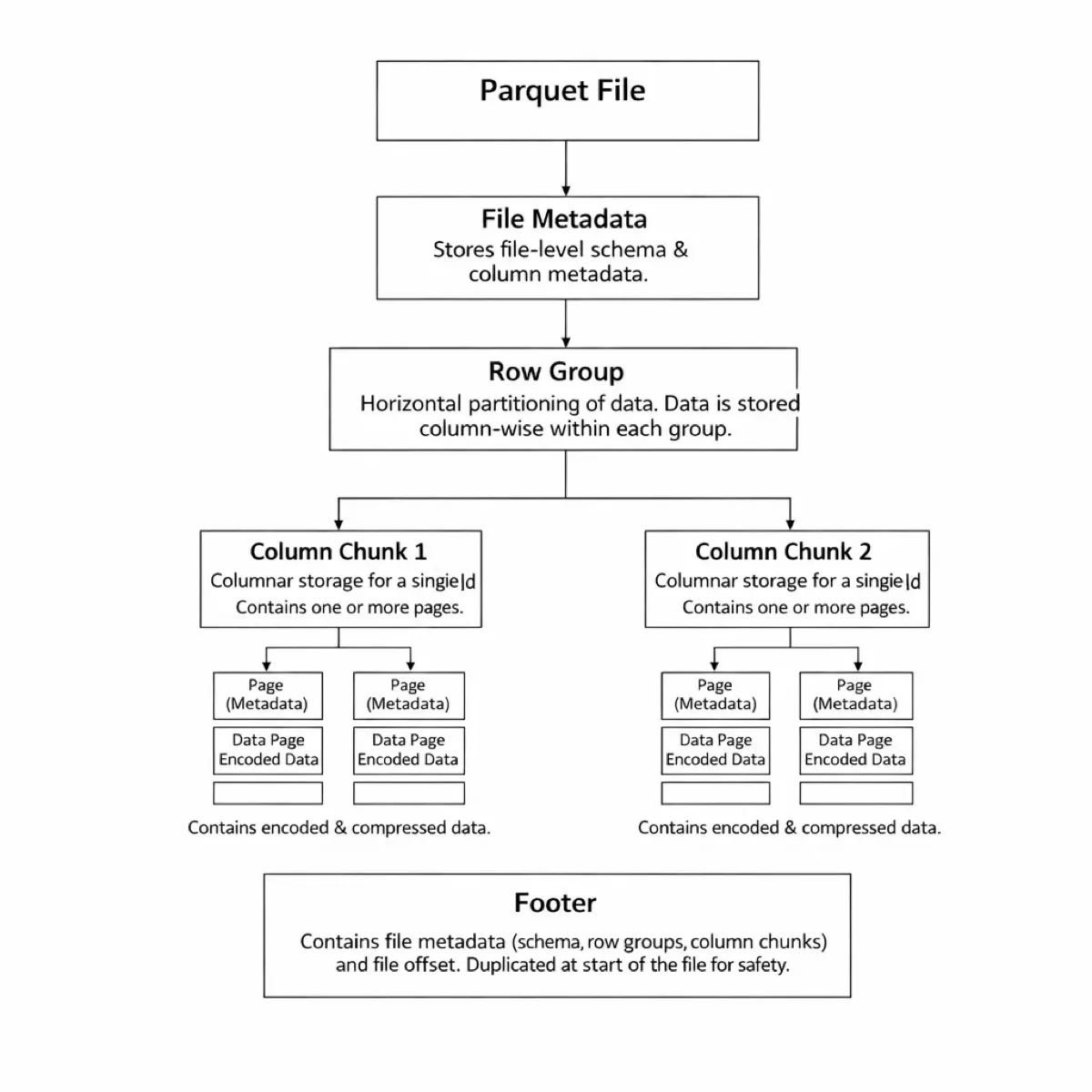
Please read more: https://parquet.apache.org/docs/file-format/
Your metadata parsing is eating you alive. Got a table with 10,000 columns for ML features? Congratulations, you’re spending 100ms+ just reading the footer. Just the footer. Not the data — the table of contents.
Row groups are a beautiful lie. The concept is elegant: partition data horizontally, store columnar within each partition. In practice? Your writer is buffering 1GB+ in RAM because you can’t flush until the entire row group is ready. I’ve seen production systems OOM because someone tried to write a wide table with default settings.
Dictionary encoding is all-or-nothing. Every column chunk gets exactly one dictionary. No exceptions. Doesn’t matter if your first million rows have 10 distinct values and your last million have 10,000. Same dictionary scope. Same suboptimal compression.
Version hell is real. Added nanosecond timestamps to the Parquet spec in 2018? Cool. Still not supported in Spark or Iceberg in 2025. Why? Because upgrading every reader implementation across every language is basically impossible.
The breaking point? Imagine working on a feature store with 50,000+ columns. A simple projection query — “give me these 10 columns” — was spending more time parsing metadata than reading data.
What F3 Actually Fixes
The F3 team didn’t just iterate on Parquet. They fundamentally rethought what a columnar format should be in 2025. And the results are stunning .
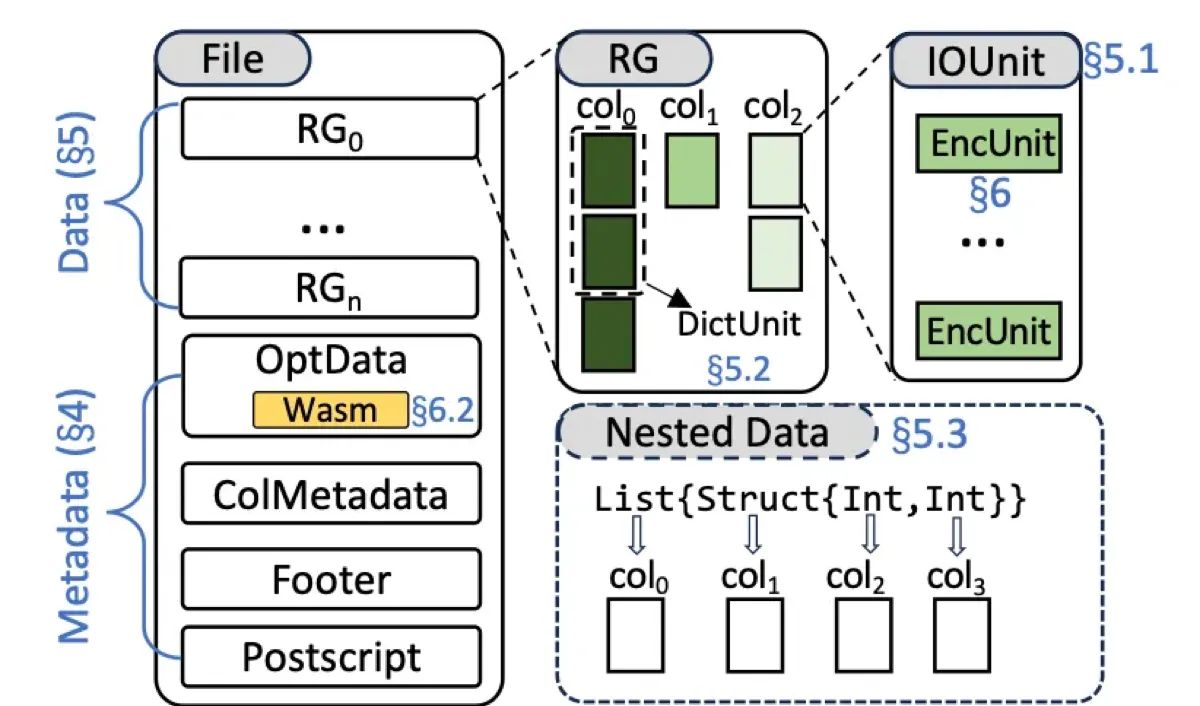
Fix #1: Metadata That Doesn’t Hate You
F3 uses FlatBuffers for all metadata. Not Thrift. Not Protocol Buffers. FlatBuffers.
Why does this matter? Zero-copy deserialization.
# What Parquet makes you do:
# 1. Read entire footer (all 50,000 columns worth)
# 2. Deserialize entire Thrift struct
# 3. Finally access your 10 columns
# What F3 lets you do:
# 1. Read footer (tiny)
# 2. Read ONLY the metadata for your 10 columns
# 3. Zero deserialization overheadThe result? For that 10,000-column table I mentioned:
- Parquet: 100ms+ metadata overhead
- F3: 10ms
That’s a 10x improvement just from not reading things you don’t need.
Fix #2: IOUnits (aka “How Writing Should Work”)
This one’s subtle but brilliant. Parquet’s row group is overloaded — it’s your logical partition, your I/O unit, and your memory flush boundary all at once. F3 decouples these:
// F3's hierarchy:
Row Group -> Logical partition (1M rows)
└─ IOUnits -> Physical I/O (8MB each)
└─ EncUnits -> Encoding boundaries
// Parquet's hierarchy:
Row Group -> Everything (logical + physical + flush boundary)The practical impact? I can write a 10GB row group without holding 10GB in memory. F3 flushes 8MB IOUnits as soon as a column fills one up. Memory usage: constant regardless of row group size.
Here’s what this looks like in practice:

Fix #3: Dictionaries That Make Sense
F3 lets you choose dictionary scope per column. Want a global dictionary across the whole file? Done. Want a local dictionary per 64K rows? Also done. Want something in between? That works too.
The research is wild: they tested 2,080 columns from real datasets and found:
- 13% compress best with local dictionaries
- 35% compress best with global dictionaries
- 52% compress best with something in-between
But here’s the kicker — if you just pick “best of global or local,” you get near-optimal compression for 88% of columns . And F3 can auto-select this at write time.
# Example: Column with changing cardinality
# First 1M rows: 10 distinct values
# Next 1M rows: 10,000 distinct values
# Parquet: One dictionary for all 2M rows
# Result: Bloated dictionary, poor compression
# F3: Separate dictionaries per scope
# Result: Small dict for first chunk, larger for second
# Overall file size: 15-20% smallerFix #4: The WebAssembly Trick
This is where F3 gets really interesting (or controversial, depending on who you ask).
The core problem: How do you add new encoding schemes without breaking every reader?
Parquet’s answer: Add it to the spec, implement it in every language (Java, C++, Rust, Go, Python…), wait 3–7 years for adoption, watch as half the readers never update.
F3’s answer: Embed the decoder in the file itself as WebAssembly.
Wait, what?
┌─────────────────────────────────────┐
│ F3 File │
├─────────────────────────────────────┤
│ Data (compressed with CustomCodec) │
│ Metadata │
│ Wasm Binary (CustomCodec decoder) │ <- This is new
└─────────────────────────────────────┘Every F3 file contains:
- The actual data (encoded)
- The metadata describing it
- The Wasm code to decode it
This means:
- Add new encodings without coordinating across implementations
- Old readers can decode new files (via embedded Wasm)
- New readers can use native code (faster) when available
- Files are self-describing and future-proof
The overhead? About 150KB per encoding. For a typical file, that’s 0.001% of the total size.
The performance hit? 15–35% slower than native code for the Wasm path. But here’s the thing — you only use Wasm as a fallback. If your reader has native support, it uses that.
What Actually Works (And What Doesn’t)
I’ve been running F3 in our feature store pipeline for three weeks. Here’s the honest assessment:
Metadata performance is transformative. Wide table queries are 5-10x faster. This alone justifies trying F3.
Write memory is predictable. No more OOM crashes on wide tables. Our writers went from “fingers crossed” to “just works.”
Compression ratios are competitive. Within 5% of Parquet, sometimes better, depending on the data.
The Wasm thing actually works. I tested with a custom encoding for time-series data. Embedded it as Wasm, readers just worked. No upgrades needed.
Ecosystem support is early. You cannot drop F3 into Spark or Snowflake yet. This is a showstopper for many teams.
Write performance is slightly slower. About 10-15% compared to Parquet in my tests. The flexibility costs something.
Documentation is academic. The SIGMOD paper is great if you have a PhD. Less great if you just want to understand the layout.
Tooling is minimal. Want a nice inspector UI like you have for Parquet? Not yet. File corruption debugging? Hope you like hex dumps.
The Verdict
F3 is the first “next-gen” columnar format I’ve seen that actually deserves the hype. The metadata design is legitimately better. The IOUnit decoupling solves real problems. And the Wasm thing — as weird as it sounds — is actually brilliant.
But it’s early. Really early. If you need Spark integration tomorrow, stick with Parquet. If you’re building something new and can tolerate rough edges, F3 is worth serious consideration.
The format’s three core principles — interoperability, extensibility, efficiency — aren’t just marketing. They’re baked into every design decision. And that’s rare.
Your Move
Try this:
- Download the F3 library : git clone https://github.com/future-file-format/F3
- Convert one of your Parquet files : Start with a wide table if you have one
- Run a projection query : Time how long it takes to read 10 columns from 10,000
- Check the memory usage : Write a file with the same row group size
- Share your results : The community needs more real-world data points
Questions for the comments:
- Are you hitting Parquet’s limits in production?
- Would you adopt F3 today, or wait for ecosystem support?
- What’s your experience with wide tables and metadata overhead?
The format wars are heating up again. And this time, we might actually get an upgrade worth the migration pain.
Reference: Zeng, X., Meng, R., Prammer, M., McKinney, W., Patel, J.M., Pavlo, A., & Zhang, H. (2025). F3: The Open-Source Data File Format for the Future. Proceedings of the ACM on Management of Data , 3(4), Article 245. https://doi.org/10.1145/3749163
Further Reading:
- GitHub: https://github.com/future-file-format/F3
- Research Paper: https://db.cs.cmu.edu/papers/2025/zeng-sigmod2025.pdf
Want to go deeper on file formats and data systems? Designing Data-Intensive Applications is the best resource for understanding how storage engines, encoding formats, and distributed systems actually work under the hood.
Comments
Loading comments...