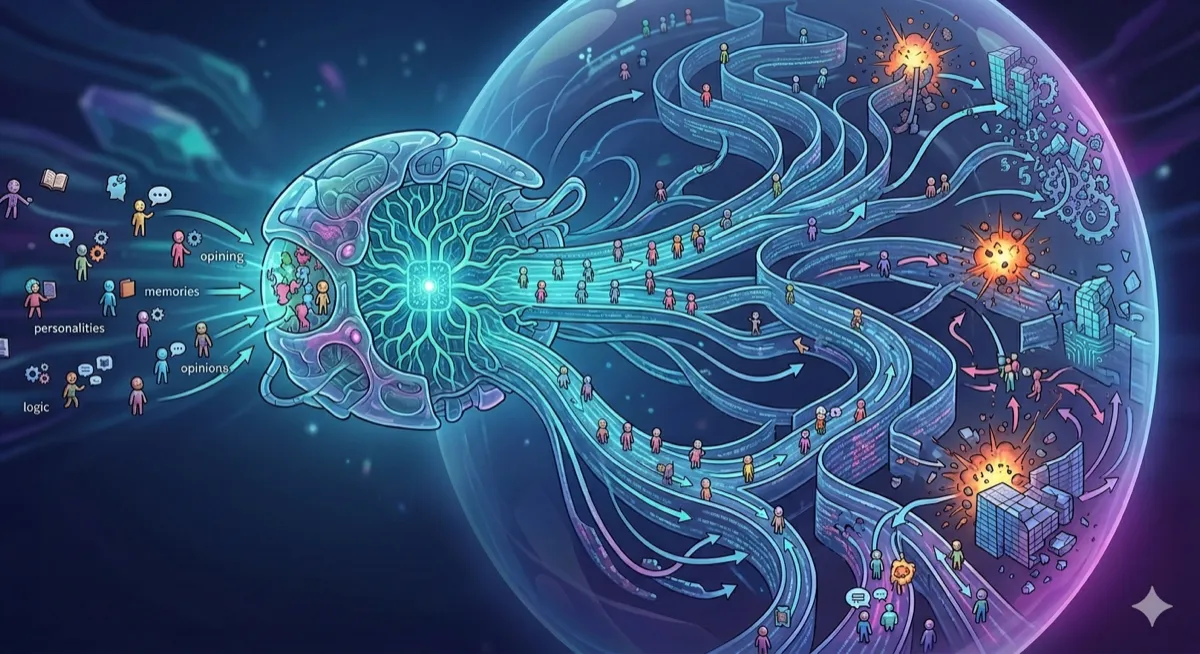
What If You Could Run the Future Before It Happens?
MiroFish doesn’t predict the future with statistics. It simulates it — spawning thousands of AI agents with memories, personalities, and opinions, then watching what breaks loose.
Open Source | Multi-Agent AI | GraphRAG | OASIS | March 2026 ~12 min read
The simulation engine that hit 45k stars
Somewhere between weather forecasting and science fiction lies an idea that researchers have quietly chased for decades: what if you could simulate a slice of society — complete with arguing, persuading, rumor-spreading, opinion-shifting humans — before an event actually unfolds? Not a survey. Not a regression. A living, breathing rehearsal.
MiroFish is a serious attempt at that idea. Built by Guo Hangjiang, a senior undergraduate in China, it hit the top of GitHub’s Global Trending list in March 2026 and has accumulated 45,000 stars. The premise is provocative: feed it seed material — a news story, a policy draft, the first 80 chapters of a classic novel — and it builds a digital world populated by thousands of AI agents who then argue, evolve, and eventually hand you a prediction report.
It’s simultaneously one of the more audacious open-source AI projects of the year and one of the most honest about what it can’t yet do. Both qualities deserve attention.
| Metric | Value |
|---|---|
| GitHub Stars | 45k (Mar 2026) |
| Agent scale (OASIS engine) | 1M |
| Pipeline stages (seed to report) | 5 |
The prediction problem nobody solved
Traditional forecasting models — whether statistical, ML-based, or agent-based in the academic sense — share a quiet assumption: the world is a system you can describe with equations. Feed in the right variables, and the outputs follow. This works reasonably well for physical systems. It works far less well for people.
People react to each other. Opinions don’t move in isolation — they spread through networks, get distorted in retelling, amplify in echo chambers, and occasionally reverse entirely when the right voice says the wrong thing at the right moment. A single viral post can redirect the trajectory of a news cycle. These are emergent dynamics — properties of the system that no single actor intends and no equation captures cleanly.
The real world doesn’t move like a math equation. It moves like a crowd — chaotic, contagious, and occasionally surprising even itself.
What MiroFish proposes is to simulate that mess directly. Instead of modeling aggregate behavior with statistics, it instantiates thousands of individual AI agents — each with their own personality, stance, and memory — and lets them interact. The prediction emerges from the chaos, not from a formula sitting above it.
Is this approach proven? Not definitively — there are no published benchmarks comparing MiroFish predictions against real outcomes. But the architecture is coherent, the underlying simulation engine (OASIS) is peer-reviewed research, and the early demos are striking enough to take seriously.
How it actually works
The pipeline has five distinct stages. Understanding each one helps separate what’s genuinely novel from what’s well-established infrastructure being orchestrated cleverly.
Stage 1: Knowledge graph construction
You upload “seed material” — a news article, financial report, policy document, or even a novel. MiroFish uses GraphRAG (Graph-based Retrieval Augmented Generation) to parse the text and extract entities and relationships into a structured knowledge graph. This becomes the bedrock reality of the simulation — who exists, how they’re connected, what pressures are at play.
Stage 2: Environment setup and agent creation
Based on the knowledge graph, MiroFish generates agent personas automatically. Each agent receives a distinct personality and background, a unique stance on the topic, long-term memory powered by Zep Cloud, and behavioral logic governing interactions. An Environment Configuration Agent then sets the simulation parameters — the rules of the world these agents will inhabit.
Stage 3: Dual-platform parallel simulation
Agents interact across two simulated social platforms simultaneously — think Twitter-like and Reddit-like environments running in parallel. The engine under the hood is OASIS, built by CAMEL-AI, which supports up to one million agents and 23 distinct social actions: posting, commenting, reposting, following, arguing. The system tracks your prediction question dynamically and updates each agent’s memory as events unfold round by round.
Stage 4: Report generation
After the simulation runs, a dedicated ReportAgent synthesizes everything. It analyzes how opinions shifted, what coalitions formed, what patterns emerged, and what the simulation suggests about the original prediction question. The output is a structured report — not a dashboard of numbers, but a narrative analysis of emergent behavior.
Stage 5: Deep interaction
The report isn’t the final stop. You can chat with individual agents in the post-simulation world to understand their reasoning. You can query the ReportAgent with follow-up questions. You can inject new variables and re-run scenarios. The “what if we change X?” loop is built into the design.
The tech stack
MiroFish isn’t built from scratch — it’s an orchestration layer over some well-chosen components. Understanding the stack helps assess both the capabilities and the constraints.
| Layer | Technology | Notes |
|---|---|---|
| Backend | Python 3.11-3.12 | Managed via uv |
| Frontend | Vue.js + Node 18+ | Runs on localhost:3000 |
| Simulation Engine | OASIS (CAMEL-AI) | Peer-reviewed; scales to 1M agents |
| Knowledge Graphs | GraphRAG | Entity + relationship extraction |
| Agent Memory | Zep Cloud | Free tier sufficient for basic use |
| LLM | Any OpenAI-SDK compatible | Recommended: Qwen-plus (Alibaba) |
| Deployment | Docker Compose or source | Ports 3000 + 5001 |
The LLM flexibility is worth underlining. The README recommends Alibaba’s Qwen-plus via the Bailian platform, but any model that speaks the OpenAI SDK format works. That means you can plug in GPT-4o, Claude, or a locally hosted model if you want to keep data off third-party APIs — a meaningful option for enterprise or research use cases.
Setting it up — what actually happens
For developers who want to get hands-on, the setup is refreshingly straightforward for a project of this complexity. Three dependencies: Node.js 18+, Python 3.11 or 3.12, and the uv package manager. Two API keys: one for your LLM provider, one for Zep Cloud (which has a free tier).
# Clone and configure
git clone https://github.com/666ghj/MiroFish.git
cd MiroFish
cp .env.example .env
# Edit .env with your API keys
# One-command install — handles root, frontend, and backend
npm run setup:all
# Fire it up
npm run dev
# -> Frontend: http://localhost:3000
# -> Backend API: http://localhost:5001# Minimum required environment variables
# LLM provider (OpenAI SDK-compatible)
LLM_API_KEY=your_api_key
LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_MODEL_NAME=qwen-plus
# Zep Cloud — agent long-term memory
# Free tier: https://app.getzep.com/
ZEP_API_KEY=your_zep_api_keyRunning hundreds of agents through multi-round simulations means many LLM API calls. The README explicitly recommends starting with fewer than 40 simulation rounds to manage costs. Budget accordingly before running large predictions.
Docker deployment is also supported — pull the image, point it at your .env, and run docker compose up -d. The compose file includes a mirror address in the comments for faster pulls in regions where Docker Hub is slow.
What you can actually do with it
The team has demonstrated three meaningfully different use cases, which together hint at the range of what’s possible.
Public opinion simulation
The primary demo involves a university public opinion event — feed in a news report, describe your prediction question, watch agents debate across simulated social platforms, and receive a report on how sentiment might evolve. This is the most polished demo and the most directly applicable to communications teams, policy analysts, and researchers studying social contagion.
Literary prediction
The most unexpected demo: the team fed the first 80 chapters of Dream of the Red Chamber — one of the four great classical novels of Chinese literature — into MiroFish and had it predict the lost ending based on how the characters would behave given their established personalities. This is partly a showcase, partly a proof that the engine isn’t domain-locked. The agents built from literary characters interact as those characters would, and something narrative-shaped emerges.
Financial and political forecasting
Flagged as “coming soon” in the README, but the architecture supports it cleanly. Inject market signals and simulate how traders, analysts, and retail investors influence each other. Upload a policy draft and model stakeholder coalition behavior. These feel like the higher-stakes applications the project is ultimately building toward.
A live demo environment is publicly accessible — it includes a pre-run simulation of a trending public opinion event that you can explore without running any infrastructure.
The part that matters: OASIS under the hood
One of MiroFish’s most credible design decisions is the choice of simulation engine. The README acknowledges it directly: MiroFish’s simulation layer is powered by OASIS, the Open Agent Social Interaction Simulations framework built by the CAMEL-AI team.
OASIS isn’t a toy. It’s peer-reviewed research published through academic channels, designed explicitly for large-scale social simulation. It supports up to one million simultaneous agents, 23 distinct social actions (the full range of what a social media user might do), and dynamic temporal memory updates across simulation rounds. The CAMEL-AI team has published findings including one notable result: LLM agents tend to exhibit stronger herd behavior than real humans — meaning simulated crowds can polarize faster than real ones.
That last point matters. It’s not a failure of the system — it’s documented behavior that users need to account for when interpreting results. A simulation that polarizes faster than reality isn’t wrong; it’s a feature whose implications you need to reason about.
Why developers should actually care
Even if you’re not building a prediction engine, MiroFish is worth studying as an architectural case study. Several patterns it implements are showing up increasingly in production AI systems:
- GraphRAG for knowledge grounding — giving agents structured, relational context rather than a flat dump of text. This is increasingly how serious RAG applications differentiate themselves from naive chunk-and-retrieve approaches.
- Persistent agent memory — using Zep to let agents remember across rounds. This is the multi-agent version of a problem every LLM engineer eventually hits: how do you make an agent that learns within a session?
- Emergent behavior as the output — designing systems where results aren’t programmed but arise from agent interactions. This is the most philosophically interesting shift — from “what does the model predict?” to “what happens when thousands of models interact?”
- Multi-platform simulation — running parallel environments simultaneously to capture how information flows differently across different social contexts.
These aren’t niche research concerns. They’re engineering problems you’ll hit building any system where multiple AI agents need to collaborate, remember, and influence each other — which describes a growing share of serious AI deployments.
The honest reckoning
A few things to be clear-eyed about before diving in:
- No benchmarks yet. The team hasn’t published comparisons between predictions and real outcomes. Demos show plausible scenarios, not validated accuracy.
- Agent bias is real. OASIS research finds LLM agents polarize faster than real humans. Simulated crowds aren’t real crowds.
- LLM costs compound fast. Hundreds of agents x many rounds x full LLM calls gets expensive quickly. Start small.
- macOS-first. Developed and tested on macOS; Windows compatibility is still being evaluated per the documentation.
- This is v0.1.0 (released December 2025). It’s powerful in concept, early in execution. Treat it as a research platform, not a production tool.
The backstory worth knowing
MiroFish was built by Guo Hangjiang, a senior undergraduate student in China. Its predecessor — BettaFish, a multi-agent public opinion analysis tool — hit number one on GitHub Trending in late 2024. MiroFish followed with the same trajectory in early 2026, eventually attracting strategic support and incubation from Shanda Group, the Chinese investment conglomerate founded by Chen Tianqiao.
The project is recruiting full-time and internship positions for people interested in multi-agent simulation and LLM applications. Given the traction, that’s not a throwaway line in the README.
What’s striking about the origin story is how student-built projects at this technical ambition level are becoming increasingly viable — not because the ideas are new, but because the infrastructure (OASIS, Zep, GraphRAG, OpenAI-compatible APIs) has matured enough that one person can assemble something genuinely interesting from existing components and ship it.
Try it
git clone https://github.com/666ghj/MiroFish.git
cd MiroFish
cp .env.example .env
npm run setup:all
npm run dev- GitHub — Open Source
- Live Demo
- OASIS Engine — CAMEL-AI
- Zep Cloud — Free tier available
MiroFish isn’t claiming to have solved prediction. It’s claiming to have built a new kind of tool for exploring it — one where the output isn’t a number but a world you can interrogate. That’s a different kind of claim, and in some ways a more honest one. Predictions are wrong. Simulations, at minimum, show you the shape of what could happen, and that visibility has its own value.
Whether that value holds up under rigorous evaluation remains to be seen. But as a technical exploration of what multi-agent AI systems can do when pointed at complex social dynamics, it’s one of the more compelling open-source projects to emerge in 2026.
If the multi-agent architecture and data pipeline design behind MiroFish has you thinking about how to build reliable systems at scale, this is the foundational text:
Designing Data-Intensive Applications by Martin Kleppmann — the book every data engineer references when reasoning about distributed systems, data flow, and the storage patterns that underpin platforms like these.
Disclaimer: This is an independent editorial analysis based on the publicly available MiroFish GitHub README and supplementary community coverage. All technical claims are sourced directly from these materials. MiroFish is a v0 open-source project — treat claims about capabilities as developer-reported, not independently benchmarked. The author has no affiliation with MiroFish, Shanda Group, or CAMEL-AI. Star counts and stats reflect the time of writing and may have changed. This article contains affiliate links — purchasing through them supports this blog at no extra cost to you.



Comments
Loading comments...